
Evaluating AI for Learning: A Framework
- May 16, 2025
- 13 minutes read



This is the first blog in our newly launched series: Harvesting Insights: AI in Agriculture, where we introduce frameworks, methods, and insights that implementers, funders, and policymakers can leverage when designing and scaling effective AI-powered agricultural tools.
As AI-powered chatbots play an increasingly important role in agricultural advisory, the key challenge lies in ensuring the quality and reliability of the advice generated by these agricultural advisory tools. In this first blog, we present an evaluation framework to assess these tools. The framework is focused on three key pillars: (i) AI Model Assessment, (ii) User Journey Assessment, and (iii) System Assessment. Designed to enable iterative learning, this framework helps teams continuously assess and improve their tools. We see this as a complement to more rigorous evaluation approaches, such as randomized controlled trials, as this evaluation framework offers an agile, early-stage method to identify strengths, gaps, and opportunities for improvement. This will contribute to a growing body of public knowledge and spark meaningful discussion on how we can effectively leverage AI to deliver targeted, timely, and relevant services to millions of smallholder farmers.
AI-Powered Virtual Assistants in Agriculture
There has been an exponential increase in actors developing AI-driven chatbots for agriculture. These virtual assistants bridge the gap between complex agronomic knowledge and on-the-ground decision-making, thereby offering real-time access to information in a range of topics such as weather, prices, and agronomic practices, often through different media and in the local language. AI-powered chatbots can augment traditional extension services by providing instant and accurate information to farmers with the goal of improving the level of personalization and relevance of such services at scale.1 Some notable AI assistants in the Indian agricultural sector are Kisan e-Mitra (a scheme information chatbot), Krishi Saathi (an AI assistant for Farm Tele Advisors working in Kisan Call Centers) and KissanAI (an agricultural co-pilot).
Given the nascency of AI-powered chatbots in the agricultural use case, the accuracy of the information generated by these chatbots is still being probed, and the scalability of the chatbots is being assessed. Inaccurate or misleading information could have serious consequences, leading to poor crop management, financial losses, or environmental damage. Developing robust evaluation mechanisms is crucial for mitigating these risks and ensuring reliability, trust, and a long-term impact.
How are Chatbots Evaluated?
Several standardized metrics already exist to assess the accuracy of the underlying AI model. For example, BLEU typically measures machine translation precision against a reference, and ROUGE measures how closely chatbot responses align with reference texts. A good example of domain-specific benchmarking comes from healthcare, where the HealthPariksha framework has been developed to test medical chatbots on their factual correctness, safety, and adherence to ethical standards. In this case, the benchmarks were based on questions from Indian patients in English and several local languages; experts reviewed the chatbot responses for how accurate and safe their medical advice was. While similar specialized benchmarks have emerged for fields such as law and finance, standardized evaluation methods are still being developed for agriculture.
Because both the needs of farmers and these tools evolve rapidly, there is a need for an iterative, farmer-centered approach focused on learning and adaptation. We call this the “missing middle“: sprints of iterative prototyping, testing, and refining based on farmer feedback after completing the technical testing, before investing in more expensive, rigorous evaluations. These iterative cycles help us learn more about the accuracy, relevance, and usability of the content and the tool itself. This missing middle is a critical step in building tools that are technically sound, user-friendly, suitable for scaling, and ready for large-scale evaluation.
Recently, organizations like the Agency Fund and Microsoft IDEAS have introduced helpful AI evaluation frameworks that emphasize rapid testing and user journey assessments as essential components. Our approach builds on and complements these efforts, with greater emphasis on the following two areas.
First, we place a strong emphasis on the iterative nature of testing and refinement. Rather than offering a prescriptive model, we present a flexible set of guiding principles for evaluating AI-enabled chatbots.
Second, our framework adopts a flexible, mixed-methods approach tailored to evaluate the different stages and dimensions of the user journey. Recognizing that no single method can capture the full picture, we draw from a broad toolkit—including observation sessions, in-depth discussions with users, lab-in-the-field (experimentation with real-world users in a sandbox environment), and A/B testing (experimentation with real-world users in a natural environment). The choice of method depends on the goal: knowledge of scalability, reliable insights, quick, targeted assessments, or deeper, contextual understanding. This adaptability ensures that the evaluation strategies stay aligned with the evolving needs of the users.
In this blog, we introduce PxD’s proposed evaluation framework; we developed it to guide our work with governments and partners as they invest in, evaluate, and iteratively improve AI tools that aim to reach and support millions of farmers.
Evaluation Framework
Our framework takes a holistic approach built on three key pillars: AI Model Assessment, User Journey Assessment, and System Assessment2 While this blog focuses on AI-driven chatbots, the framework can be replicated for AI-driven tools that do not have an interactive chatbot feature and are used in the agricultural domain. to ensure that chatbots are not only functional but also effective in real-world conditions. The pillars are structured to generate actionable insights that directly inform improvements to the chatbot tool. Rather than serving as a prescriptive checklist, this framework is intended as a collaborative approach, enabling our close partnerships with the development team to support continuous, iterative enhancement of the chatbot service.
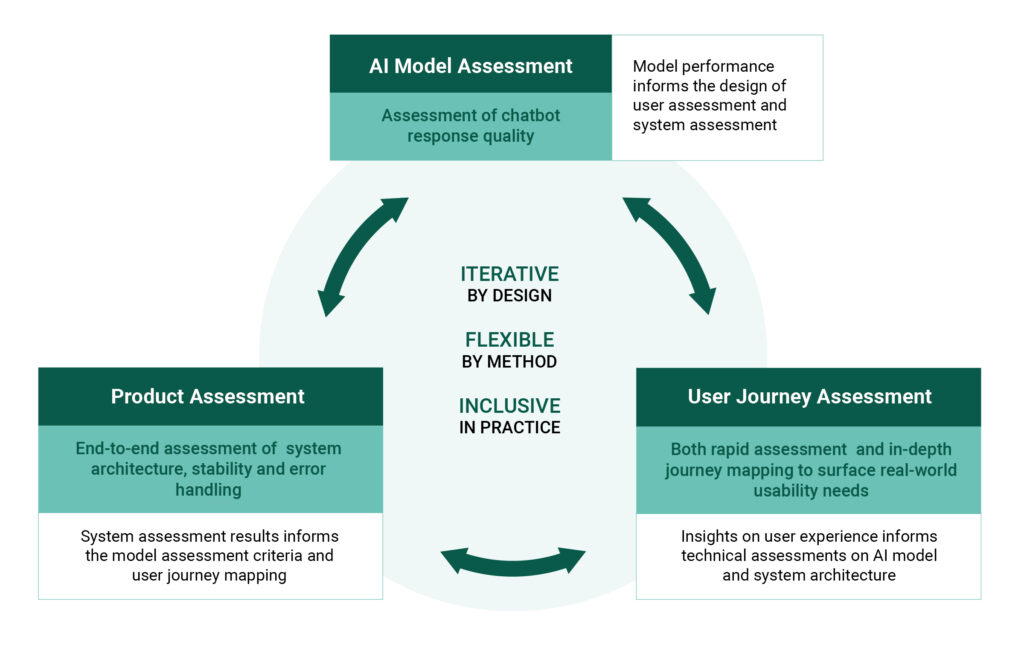
1. AI Model Assessment
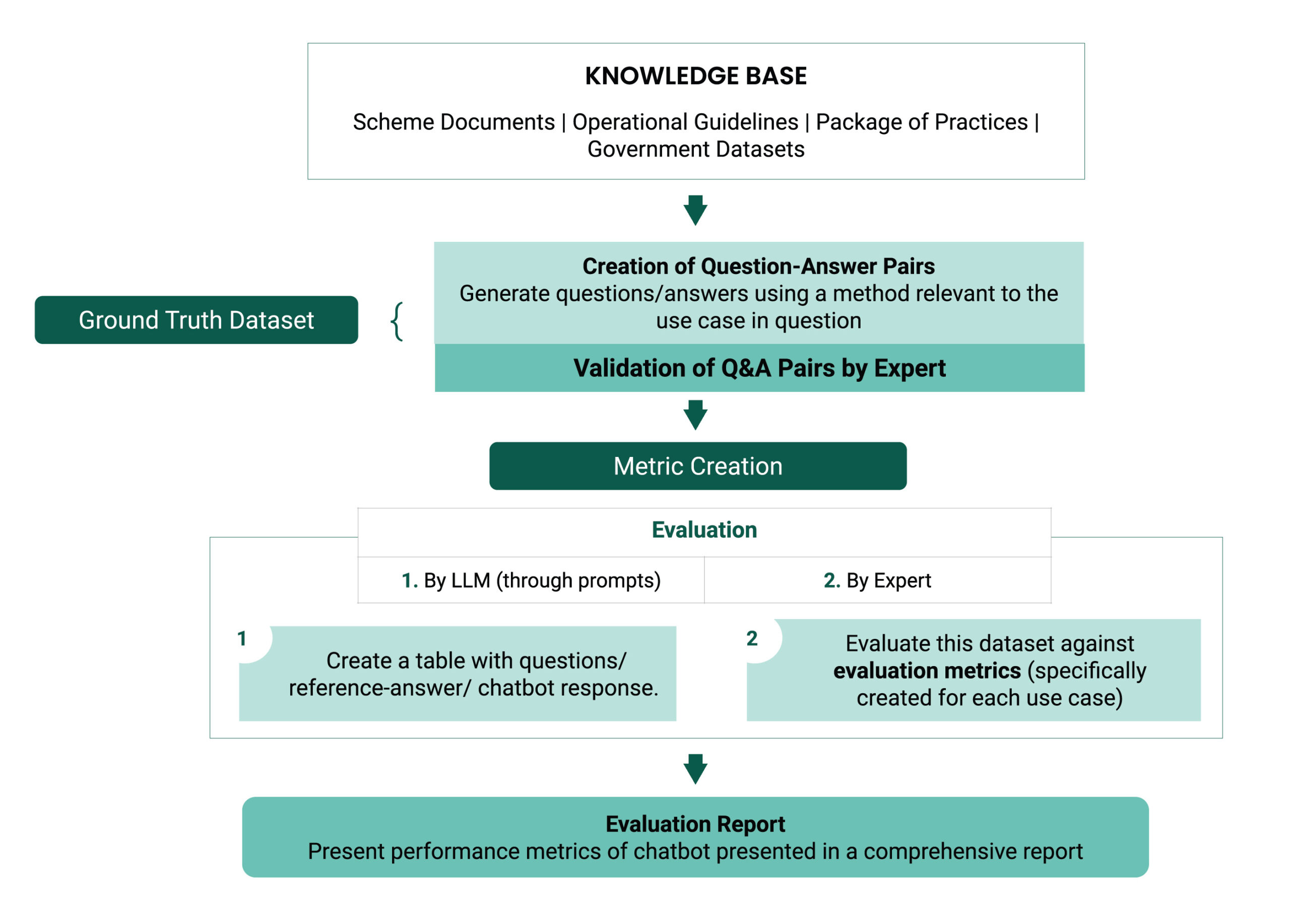
The first pillar involves assessing the underlying AI model and allows in-depth assessment of the chatbot responses. This pillar centers on the creation and validation of a ground-truth dataset3A ground truth dataset-also known as a gold standard or reference dataset-is a carefully curated collection of data with verified correct answers, used to evaluate or train models for accuracy and reliability.. This benchmark dataset comprises curated question‑answer pairs that represent the full breadth of expected types of queries across use cases and languages, sourced from verified knowledge bases (e.g., scheme FAQs, operational guidelines, expert‑validated agronomic resources like package-of-practices, and government datasets).
The method for creating question–answer pairs is based on the domain or use case of the chatbot being evaluated. In fact‑based areas such as scheme information, prompt‑driven large language models (LLMs) are often used to generate a comprehensive set of Q&A pairs. By contrast, agronomic or other specialized domains require expert‑curated4The type of experts that are involved in the ground-truth process depend on the use case at hand. For example, agronomists will be on the panel for a pest management or nutrient management related chatbot, whereas for scheme information bots, scheme officers or policy implementation experts will be involved.ground-truth datasets to capture nuanced, field‑validated knowledge. Supplementing these approaches with real user queries, where available, ensures the dataset accurately reflects farmers’ actual interactions with chatbots.
Domain experts then review and validate the dataset of Q&A pairs to ensure its completeness, accuracy, and real‑world relevance. This step is essential since it provides a reliable benchmark against which chatbot responses can be judged in context.
Next, the metrics for chatbot responses are defined. Some metrics, such as relevance, are domain‑agnostic and can be applied consistently across all agri‑chatbots. Others, like actionability, which gauges the practicality of advice given the farmers’ real‐world constraints, are domain‑specific and tailored to each chatbot’s focus area.
The assessment process then begins by aligning chatbot responses with the reference answers in the ground truth dataset. Using the metrics, responses are assessed in two processes:
- Assessment by LLM: Using prompting techniques, LLM capabilities are used to assess responses on a pre-defined set of metrics.5While it may seem counter-intuitive to use LLMs to evaluate LLMs, a growing body of literature demonstrates the utility of this approach when thoughtfully deployed. Generally, LLM-as-a-judge methods are paired with human-in-the-loop methods to ensure that results are objectively validated . Using LLM-as-a-judge allows for rapid iteration and scalability, while the human-in-the-loop acts as a expert review process.
- Assessment by Expert: Using similar prompting techniques, in the form of a Scoring Rubric, a domain expert carries out a scoring exercise on a subset of chatbot responses. The results are used to validate the LLM scoring.
Based on this assessment, interested parties receive metric-wise results and tailored recommendations—for example, machine learning engineers get insights into model errors, while product teams receive guidance on addressing real-world constraints.
It is important to recognize the limitations of model assessment, particularly for scientific and domain-specific content like agriculture. Unlike foundational models, which have widely accepted benchmarks, the agricultural domain does not have a standardized framework for evaluating knowledge-intensive, context-specific content. This lack of standardization makes it difficult to ensure consistency and comparability across evaluations and it raises questions about what constitutes “correct” or “accurate” information. Moreover, the inherently evolving nature of agricultural knowledge, driven by local practices, changing climate, and new scientific insights, adds another layer of complexity. As a result, assessments must balance the need for rigor with flexibility; any benchmark represents a best-effort approximation rather than a definitive gold standard.
Given the nuanced and evolving nature of agricultural decision-making and the “black box” nature of even the best-performing LLMs, rigorous, real-world evaluation through an RCT or other impact evaluation is still an essential final step in the evaluation process before any products can be delivered at scale.
2. User Journey Assessment
The second pillar of the framework focuses on User Journey Assessment, which comprises two critical components:
- A rapid assessment for immediate usability checks and
- A detailed user journey assessment to understand patterns of engagement and feedback.
The rapid assessment is conducted with a small group of users, such as farmers or extension workers, to flag any accessibility or interface challenges that could hinder meaningful use of the chatbot. In parallel, expert reviewers identify any glaring response inaccuracies in chatbot responses. This phase acts as a checkpoint and is the only prescriptive component of the framework. Once the basic functionality and content quality are validated, and we can classify the chatbot as a minimum viable product, the tool moves into more resource‑intensive assessments. For example, if users struggle to find the query text box or if responses consistently include factual errors, these issues are addressed at this early stage, ensuring that later evaluations focus on the tool’s actual value rather than fixable design flaws.
Once basic usability is established, the user journey assessment captures structured feedback from groups of more diverse and representative users, including different genders, geographies, farmer types (e.g., smallholders vs. large landowners), and levels of digital literacy. A chatbot may perform well on technical metrics like accuracy, but if its responses aren’t accessible or actionable by the farmers, its real-world impact remains limited. That is why this pillar emphasizes the capture of feedback across the full lifecycle of interaction—from discovery to continued usage. We assess key stages such as how users learn about the tool, how they begin using it, how they look for and understand information, what happens when expectations aren’t met, and what encourages users to return.
To do this, we apply a multi-method approach. Platform analytics help us understand usage patterns like session length and repeat engagement. Observation sessions reveal on-the-ground challenges—technical, linguistic, and contextual. Farmer surveys gather direct feedback on usability, clarity, and trust, using multimodal methods such as in-person and phone surveys. Agile experimentation (like A/B testing and field pilot studies) also enables us to trial different features and learn what works for users and what does not.
3. AI Product Assessment
The third pillar focuses on the technical performance of a chatbot—i.e., how well it functions as a system. This includes measuring standard system-health-check metrics, such as latency (response time), uptime, and error handling. Since agri-domain chatbots pull data from various agricultural databases and APIs (including government datasets), we also measure integration stability, i.e., how well the chatbot manages system dependencies.
Principles Underpinning the Framework
This evaluation framework is grounded in three core principles across the three pillars:
- Iterative by design: The processes of testing and of improving the AI model, user experience, and system design do not occur in isolation—they evolve in tandem. For instance, the initial model performance may be assessed for relevance and empathy using ground truth data curated by selected experts. But evaluation of the effects of the tool on farmer comprehension and behavior may reveal that the training dataset needs substantial augmentation. Similarly, assessment of the overall user experience may reveal an increased latency of certain devices or a mishandling of unanticipated outlier queries, which prompt further improvements to backend infrastructure or conversation-flow management.
- Flexible in method: Iterative assessment strategies must remain flexible and context-aware in order to balance speed with rigor while responsibly managing risks. This approach uses a diverse toolkit, including observational sessions, lab-in-the-field experiments, A/B testing with farmers, and experiments to identify effective tool features, message tones, and other design parameters.
- Inclusive in practice: It is essential to ensure that feedback from diverse farmer groups, especially those from marginalized communities, is meaningfully incorporated into the iterative process of testing and refinement. The scope and relevance of the targeted advice offered by AI-enabled tools are shaped by the data that the tools are trained on and continuously improved with. Without deliberate effort, developers of these tools risk over-relying on the perspectives of selected experts or the experiences of easily accessible farmers, thereby reinforcing existing inequalities.
Roadmap to Large-Scale Evaluations
With the rapid advancement of AI-enabled tools, it is essential first to understand user behavior and tinker with the tool’s design to drive sustained use of and trust in the tool. This understanding should precede large-scale impact evaluations focused on outcomes like yield and income. We propose using a flexible suite of observational and experimental assessment methods to gather knowledge of how real-world users interact with these tools. Our iterative learning process allows development teams to refine and improve products in response to user needs and contextual realities. By prioritizing agile learning before committing to rigorous randomized evaluations, we not only enhance the likelihood of finding a measurable impact but also lay the groundwork for sustainable adoption at scale.
In subsequent posts, we will explore each assessment pillar in more depth, focusing on key questions that would benefit from broader discussion in the field. For example:
- How do we build effective training and test datasets for fine-tuning and evaluation?
- How can reliable evaluation insights support government decision-making, product design, and policy?
- How can evaluation frameworks support long-term learning, thereby helping us design systems that improve over time?
This framework has been presented to stakeholders who are developing such solutions and to AI experts, and we are now working to test the framework in real-life settings. We welcome feedback, collaboration, and new perspectives to co-develop this framework to ensure more effective, user-centric solutions across domains.

Stay Updated with Our Newsletter

Make an Impact Today

